Jointly Learning Audio and Visual Patterns with Deep Neural Networks
Given a collection of images and spoken audio captions, the Inventors present a method for discovering word-like acoustic units in the continuous speech signal and grounding them to semantically relevant image regions. For example, if the model is given an utterance containing spoken instances of the words “lighthouse,” it can associate it with images containing lighthouses. This technique is relevant to many applications in spoken language processing.
Researchers
-
joint acoustic and visual processing
United States of America | Granted | 10,515,292
Figures
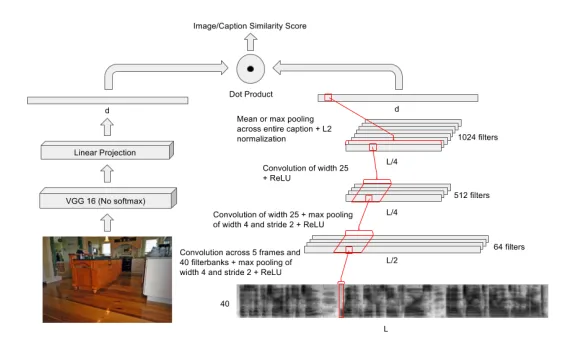
The architecture of the audio/visual neural network with the embedding dimension denoted by d and the caption length by L. Separate branches of the network model the image and the audio spectrogram, and are subsequently tied together at the top level with a dot product node which calculates a similarity score for any given image and audio caption pair.
Technology
The Inventors train a deep multimodal embedding network with a vast repository of spoken captions and image data to map entire image frames and entire spoken captions into a shared embedding space. The trained network can then be used to localize patterns corresponding to words and phrases within a spectrogram, which is a visual representation of the spoken caption’s spectrum of frequencies, as well as visual objects within the image by applying it to small sub-regions of the image and spectrogram. The model is comprised of two branches, one which takes as an input images and the other which takes as input spectrograms.
Given an image and its corresponding spoken audio captions, the Inventors apply grounding techniques to extract meaningful segments from the caption and associate them with an appropriate subregion of the image (i.e. a bounding box around the area of interest). Once a set of proposed visual bounding boxes and acoustic segments for a given image/caption pair are discovered, the multimodal network is used to compute a similarity score between each unique image crop/acoustic segment pair. The resulting regions of interest are separated out and a clustering analysis is performed to establish affinity scores between each image cluster and each acoustic cluster. This model is used to associate images with the waveforms representing their spoken audio captions in untranscribed audio data.
Problem Addressed
Humans are capable of discovering words and other elements of linguistic structure in continuous speech at a very early age, a process proven difficult for computers to emulate. It is inherently a joint segmentation and clustering problem, made difficult by many sources of variability. While conventional, supervised automatic speech recognition (ASR) systems have recently made strides due to deep neural networks (DNNs), their application is limited as they require vast amounts of costly text transcription. The Inventors’ method of acoustic pattern discovery can discover word and phrase categories from continuous speech at the raw signal level with no transcriptions or conventional speech recognition, and jointly learn the semantics of those categories via visual associations. The method of acoustic pattern discovery runs in linear time, vastly superior to previous efforts.
Advantages
• Largest scale unsupervised acoustic pattern discovery network
• Model can be extended to learn other languages, even those without a written text
• Network is highly scalable and can run in linear time, vastly superior to existing methods
Publications
Harwath, David, Antonio Torralba, and James R. Glass. "Unsupervised Learning of Spoken Language with Visual Context." Computer Science and Artificial Intelligence Laboratory, Massachusetts Institute of Technology, Cambridge, MA 02115.
License this technology
Interested in this technology? Connect with our experienced licensing team to initiate the process.
Sign up for technology updates
Sign up now to receive the latest updates on cutting-edge technologies and innovations.